Get in touch
Bugs are not failures — they are signals. Every bug is the codebase telling you something true about your assumptions. The difference between a junior developer and a seasoned engineer is rarely whether they write bugs. It's what they do when they find one.
Here is a comprehensive guide to handling bugs with the discipline and clarity that separates professional engineering from others

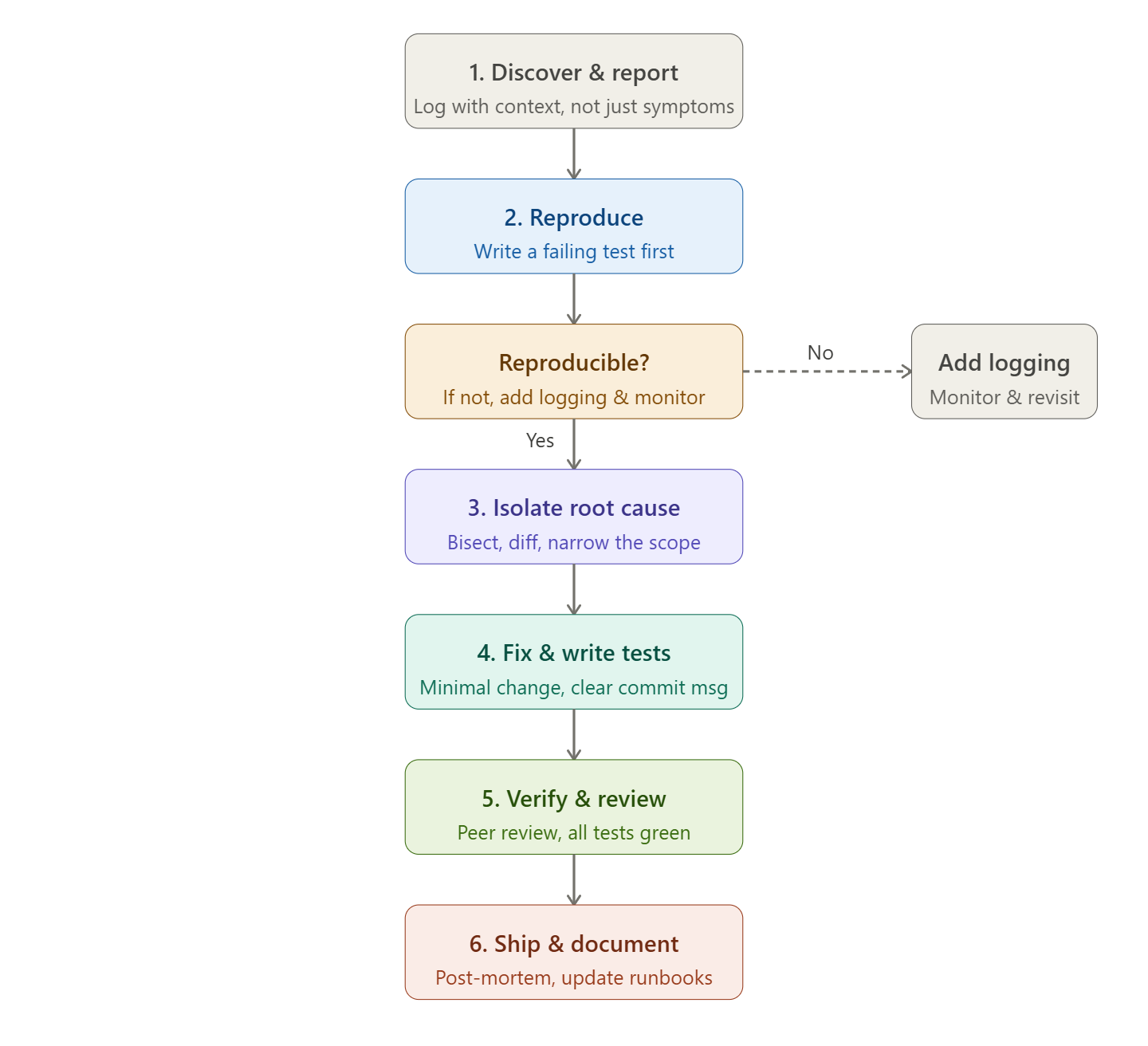
The moment a bug is discovered, the impulse is to start poking at code. Resist it. Before writing a single line, document what you know.
A good bug report answers: what happened, what was expected, how to reproduce it, what environment it occurred in (OS, browser, version, deployment), and any logs or screenshots. Vague reports like "it's broken in prod" waste hours. Precise reports like "users with admin roles get a 403 on /api/export when feature_x flag is enabled" save them.
Even if you found the bug yourself, write it down. Memory is unreliable under pressure, and your future self (and teammates) will thank you.
You cannot fix what you cannot see. Reproduction is not a formality — it is the foundation of everything that follows.
Write a failing test before you touch the source code. This does two things at once: it proves the bug exists in a controlled, repeatable way, and it gives you a pass/fail signal for when you fix it. If you cannot write a test, write a script, a curl command, or a step-by-step sequence in the ticket. The goal is to reduce the bug to its smallest possible, most reliable form.
If you cannot reproduce it at all, you are not ready to fix it. Add logging, instrument the suspicious code path, and monitor until the evidence accumulates. Fixing an unreproducible bug is guessing with extra steps.
A bug usually has a visible symptom (a crash, a wrong value, a timeout) and a root cause (a race condition, an off-by-one error, an incorrect assumption). Most developers fix the symptom. Professional developers fix the root cause.
Use binary search to narrow down the source: git bisect to find which commit introduced the regression, comment out code sections to find the responsible block, compare working vs broken data to find the discriminating factor. Read error messages literally — they often point directly at the cause.
Ask yourself: "Why does this happen?" then ask again. The first answer is usually the symptom reworded. The second or third answer is usually the root cause. Once you know exactly what is wrong and why, the fix is often obvious.
A good bug fix is minimal, surgical, and purposeful. It changes only what needs to change — no opportunistic refactors, no "while I'm in here" cleanups bundled in. Those can go in a separate PR.
Understand the full context of the code you are changing. What does this function contract? What other callers does it have? What invariants does the surrounding system assume? A fix that works in isolation but breaks an implicit contract somewhere else is just a different bug.
Write tests that would have caught this bug originally. Consider edge cases: the empty string, the null value, the zero, the overflow, the concurrent write. Your fix should make the failure mode impossible, not just less likely.
Never self-merge a bug fix in production — especially not a time-pressured one. Urgency is exactly when review matters most, because urgency is when judgment degrades.
Ask a peer to review the diff with fresh eyes. Show them the test. Explain what changed and why. A good reviewer will catch the regression you introduced, the edge case you missed, or the simpler approach you were too close to see.
Run the full test suite. Check that linting passes. If you have a staging environment, deploy there first and smoke-test the affected flow manually. Confirm the bug no longer appears and that nothing adjacent has broken.
Write a clear, descriptive commit message. Not "fix bug" — that conveys nothing. Something like "Fix admin 403 on export when feature_x enabled — wrong capability check in middleware" is useful to the next person who reads it, which might be you at 2 a.m. in six months.
If the bug affected users, communicate what happened in plain language: what the issue was, how long it was present, who was affected, and what was done. You do not need to make it sound worse than it was, but you do need to be honest. Users and stakeholders tolerate bugs. They do not tolerate being kept in the dark.
Update any relevant runbooks, internal docs, or monitoring dashboards so the team can detect or prevent this class of bug faster next time.
This is the step most developers skip. It is also the one that compounds the most value.
For any non-trivial bug — especially one that reached production — hold a blameless retrospective. The goal is not to find out who caused the bug. The goal is to understand how the system's design, process, or tooling allowed the bug to exist and escape detection. Those are the things you can actually change.
Ask: Where did our tests fail us? Was the bug reviewable and did review not catch it? Was there a gap in monitoring? Was there an assumption in the design that turns out to be wrong? Then fix those things. A team that runs post-mortems and acts on them gets measurably better over time. A team that does not repeats the same classes of bugs indefinitely.
Professional bug handling is not really about technique — it is about attitude. It requires the patience to reproduce before diagnosing, the humility to get a second pair of eyes, the care to document what you learned, and the discipline to address root causes rather than paper over symptoms.
Bugs are part of the job. How you handle them tells your team everything about your reliability as an engineer.
Your email address will not be published. Required fields are marked *



